All Categories
Featured
Table of Contents
Amazon currently generally asks interviewees to code in an online record file. Yet this can vary; it might be on a physical whiteboard or a digital one (Answering Behavioral Questions in Data Science Interviews). Examine with your recruiter what it will certainly be and exercise it a lot. Since you understand what concerns to expect, allow's focus on how to prepare.
Below is our four-step preparation strategy for Amazon data scientist candidates. Prior to spending tens of hours preparing for an interview at Amazon, you ought to take some time to make certain it's really the ideal business for you.

Exercise the technique utilizing example concerns such as those in section 2.1, or those about coding-heavy Amazon settings (e.g. Amazon software growth designer interview overview). Method SQL and programs concerns with medium and tough level instances on LeetCode, HackerRank, or StrataScratch. Take an appearance at Amazon's technical subjects web page, which, although it's made around software growth, ought to provide you an idea of what they're looking out for.
Keep in mind that in the onsite rounds you'll likely need to code on a white boards without being able to execute it, so exercise writing through issues on paper. For artificial intelligence and data questions, offers on the internet training courses made around statistical probability and other valuable subjects, some of which are free. Kaggle also provides complimentary training courses around initial and intermediate equipment understanding, as well as information cleaning, data visualization, SQL, and others.
Facebook Interview Preparation
Make certain you contend the very least one tale or example for each of the concepts, from a large range of settings and projects. A terrific method to practice all of these various kinds of inquiries is to interview on your own out loud. This may seem weird, but it will substantially enhance the means you connect your responses throughout an interview.

One of the main difficulties of data scientist meetings at Amazon is connecting your different responses in a means that's simple to understand. As a result, we highly recommend practicing with a peer interviewing you.
They're not likely to have expert understanding of interviews at your target company. For these factors, numerous candidates miss peer mock interviews and go right to mock interviews with a professional.
Behavioral Questions In Data Science Interviews

That's an ROI of 100x!.
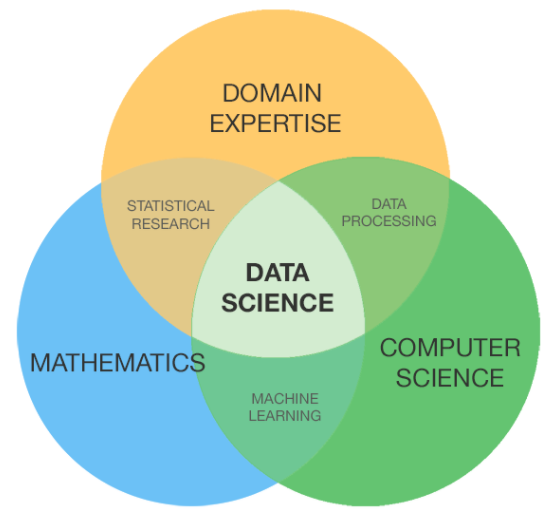
Traditionally, Data Science would certainly concentrate on maths, computer science and domain expertise. While I will quickly cover some computer scientific research principles, the bulk of this blog will primarily cover the mathematical fundamentals one may either require to clean up on (or also take an entire course).
While I comprehend a lot of you reviewing this are a lot more mathematics heavy by nature, realize the bulk of data scientific research (attempt I say 80%+) is collecting, cleansing and processing information into a valuable form. Python and R are one of the most popular ones in the Information Scientific research space. However, I have actually also come throughout C/C++, Java and Scala.
Building Career-specific Data Science Interview Skills

It is common to see the bulk of the data scientists being in one of two camps: Mathematicians and Database Architects. If you are the second one, the blog site won't assist you much (YOU ARE CURRENTLY AWESOME!).
This may either be accumulating sensor information, parsing web sites or performing studies. After collecting the data, it needs to be transformed right into a functional form (e.g. key-value shop in JSON Lines documents). As soon as the information is collected and placed in a functional format, it is vital to perform some data quality checks.
Mock Coding Challenges For Data Science Practice
In situations of scams, it is extremely usual to have hefty course imbalance (e.g. only 2% of the dataset is real scams). Such info is essential to select the suitable options for feature engineering, modelling and design evaluation. To find out more, examine my blog on Scams Detection Under Extreme Class Inequality.
In bivariate analysis, each feature is contrasted to other attributes in the dataset. Scatter matrices allow us to discover surprise patterns such as- features that should be engineered together- features that may require to be eliminated to avoid multicolinearityMulticollinearity is in fact an issue for several versions like direct regression and therefore requires to be taken care of as necessary.
In this section, we will discover some common attribute design methods. Sometimes, the function on its own may not provide valuable details. Envision using internet use information. You will certainly have YouTube individuals going as high as Giga Bytes while Facebook Messenger individuals use a number of Mega Bytes.
Another concern is using categorical values. While specific values prevail in the data scientific research world, realize computers can only comprehend numbers. In order for the categorical values to make mathematical sense, it requires to be changed right into something numeric. Commonly for specific values, it is usual to do a One Hot Encoding.
Facebook Data Science Interview Preparation
At times, having way too many sporadic dimensions will certainly obstruct the efficiency of the version. For such scenarios (as typically performed in photo acknowledgment), dimensionality decrease algorithms are made use of. An algorithm commonly made use of for dimensionality decrease is Principal Components Evaluation or PCA. Learn the technicians of PCA as it is likewise among those subjects amongst!!! For even more details, check out Michael Galarnyk's blog site on PCA utilizing Python.
The usual classifications and their sub groups are described in this area. Filter methods are usually utilized as a preprocessing step. The choice of functions is independent of any kind of maker learning formulas. Instead, features are picked on the basis of their ratings in numerous analytical tests for their relationship with the outcome variable.
Usual methods under this group are Pearson's Correlation, Linear Discriminant Evaluation, ANOVA and Chi-Square. In wrapper techniques, we try to utilize a part of features and train a design using them. Based upon the inferences that we draw from the previous version, we choose to include or get rid of functions from your part.
Mock Interview Coding
Common methods under this group are Forward Selection, Backwards Elimination and Recursive Function Elimination. LASSO and RIDGE are typical ones. The regularizations are offered in the formulas below as reference: Lasso: Ridge: That being claimed, it is to comprehend the mechanics behind LASSO and RIDGE for interviews.
Not being watched Learning is when the tags are unavailable. That being stated,!!! This mistake is sufficient for the job interviewer to terminate the interview. Another noob blunder individuals make is not normalizing the attributes prior to running the version.
Thus. Guideline. Direct and Logistic Regression are the most basic and generally made use of Artificial intelligence formulas out there. Prior to doing any evaluation One usual interview slip individuals make is starting their evaluation with an extra intricate version like Semantic network. No question, Semantic network is extremely exact. Nevertheless, criteria are necessary.
{kind=link}
Latest Posts
Mock Interviews For Software Engineers – How To Practice & Improve
How To Crack Faang Interviews – A Step-by-step Guide
How To Study For A Software Engineering Interview In 3 Months